I have long known about OpenRefine (previously Google Refine) which is a tool for working with data, manipulating and cleaning it. As of version 3.0 (May 2018), OpenRefine included a Wikidata extension, allowing for extra reconciliation and also editing of Wikidata directly (as far as I understand it). You can find some documentation on this topic on Wikidata itself.
This post serves as a summary of my initial experiences with OpenRefine, including some very basic reconciliation from a Wikidata Query Service SPARQL query, and making edits on Wikidata.
In order to follow along you should already know a little about what Wikidata is.
Starting OpenRefine
I tried out OpenRefine in two different setups both of which were easy to set up following the installation docs. The setups were on my actual machine and in a VM. For the VM I also had to use the -i option to make the service listen on a different IP. refine -i 172.23.111.140
Getting some data to work with
Recently I have been working on a project to correctly add all Tors for Dartmoor in the UK to Wikidata, and that is where this journey would begin.
This SPARQL query allowed me to find all instances of Tor (Q1343179) on Wikidata. This only came up with 10 initial results, although this query returns quite a few more results now as my work has continued.
SELECT ?item ?itemLabel ?country ?countryLabel ?locatedIn ?locatedInLabel ?historicCounty ?historicCountyLabel
WHERE
{
?item wdt:P31 wd:Q1343179.
OPTIONAL { ?item wdt:P17 ?country }
OPTIONAL { ?item wdt:P131 ?locatedIn }
OPTIONAL { ?item wdt:P7959 ?historicCounty }
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}Code language: JavaScript (javascript)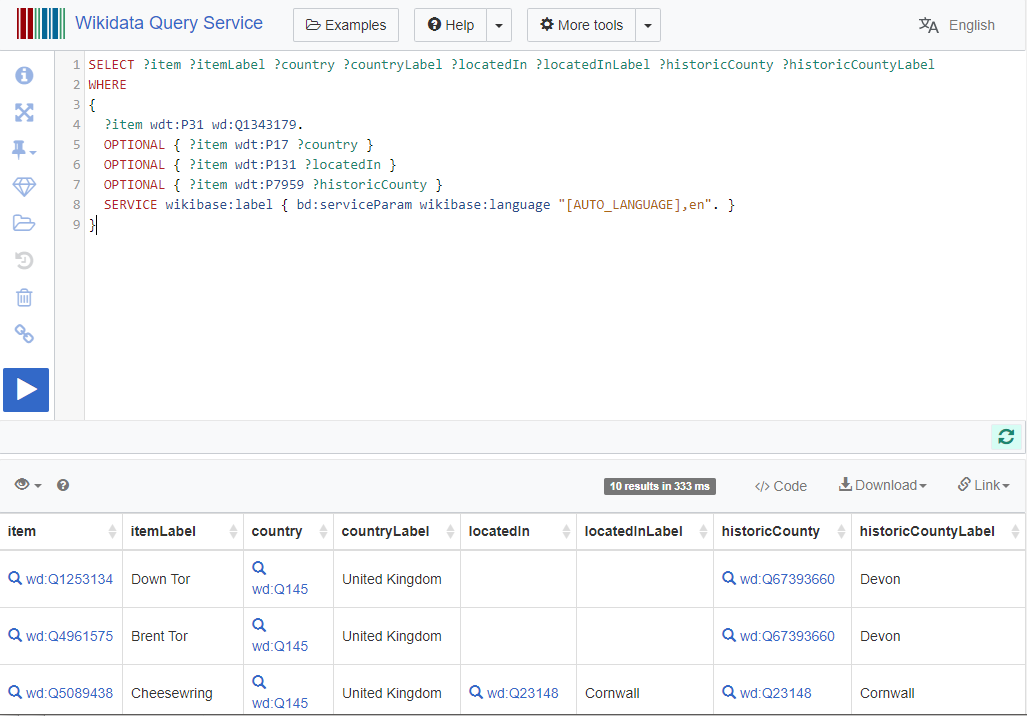
And I used the download CSV file option for my data set to load into OpenRefine.
This may not be the best way to work with SPARQL and OpenRefine, but after reading the docs this is where I ended up, and it seemed to work quite well.
Loading the data
One of the first options that you’ll see is the option to load a file from your computer. This file can be in multiple formats, CSV included, so this loading process from the query service was straight forward. It’s nice to see how many options there are for different data formats and structures. Even loading data directly from Google sheets, or from the Clipboard is supported.
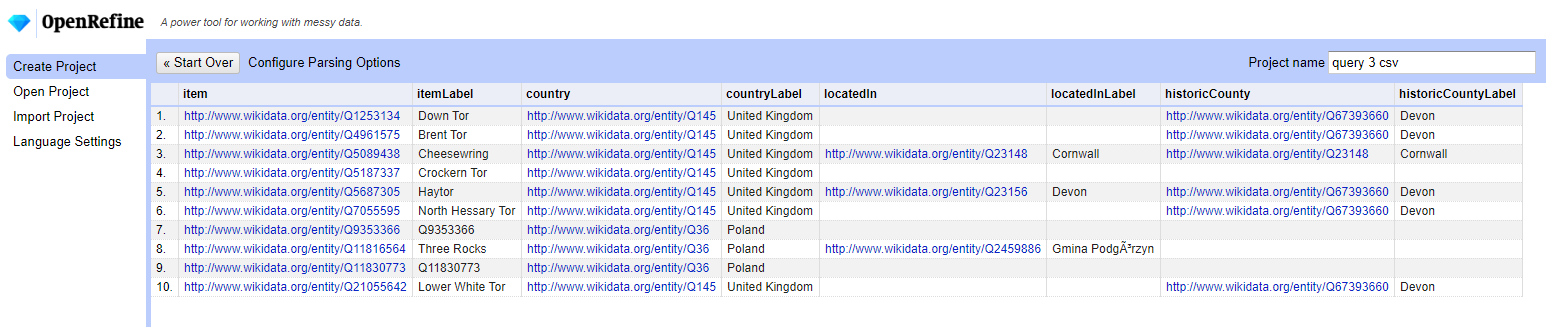
I picked a project name, hit the “Create Project” button, and my data was loaded!
Connecting to Wikidata
After a quick look around the UI I found the Wikidata button with the menu item “Manage Wikidata account”. Clicking on this prompted me to log in with my Username and Password.
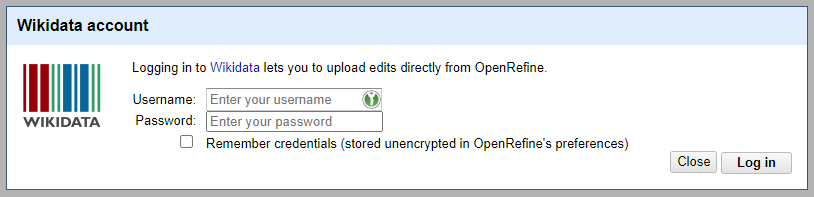
In most cases you probably don’t want to enter your password into any 3rd party application, OpenRefine included. MediaWiki, and thus Wikidata, allows you to create separate passwords for use in applications that have slightly restricted permissions. You can read the MediaWiki docs here and find the page to create them on Wikidata here.
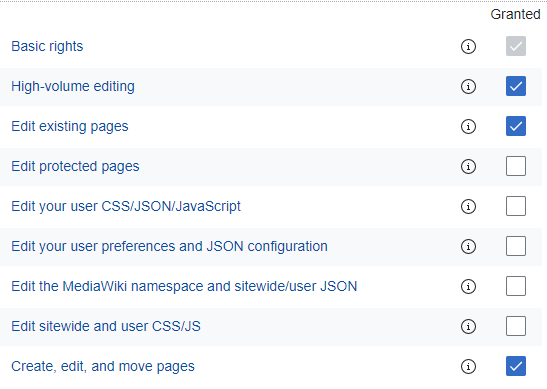
I created a new “bot” with the name “OpenRefine”, and a few basic rights that I figured OpenRefine might need, including:
- Basic rights
- High-volume editing
- Edit existing pages
- Create, edit, and move pages
This new account, with the username and password that is generated as part of this process, could then be used to log into OpenRefine without sharing the password of my main account.

Reconcile & Edit
This basic example does not use OpenRefine at a high level, and there is still a lot of cool magic to be explored. But as a first step, I simply want to make a couple of basic edits.
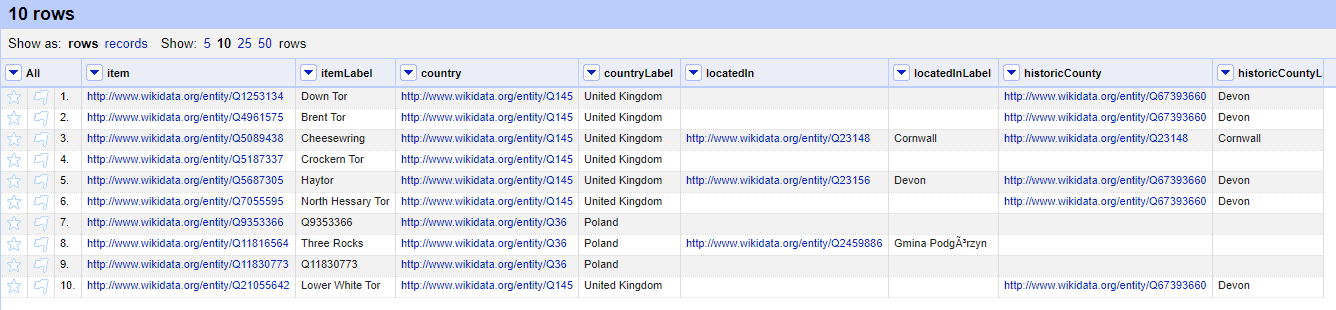
Looking at the list of tors I could see some that I knew that had a historic country value set, but did not include a value for located in. So this is where I started, manually filling the gaps in the locatedIn column (you can see this below where locatedIn has a value, but the locatedInLabel does not.
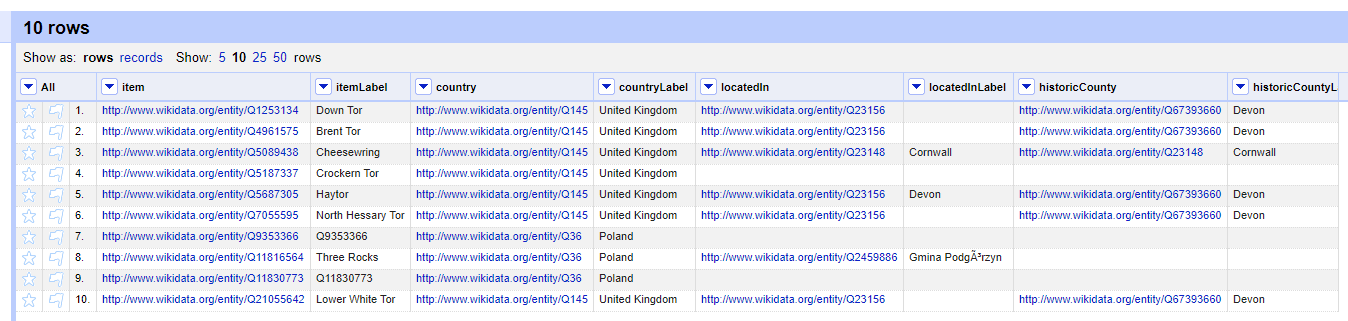
Next to connect this currently arbitrary collection of data that I have loaded from a CSV to Wikidata in some way with a bit of simple ID based reconciliation. OpenRefine has a handy feature for just this case that can be found in the “Reconcile” >> “Use values as identifiers” option of the column that you want to reconcile. In my case, this is the item column and also the locatedIn column that I had altered, both of which are needed for the edits.
Next I tried the “Upload edits to Wikidata” button, which brought me to a page allowing me to map my table of data to Wikidata statements. For this first batch of edits, this involved dragging the item field into the item space on the page, and then filling out the property used for my data, and dragging locatedIn into place.
Once finished it looked something like this:
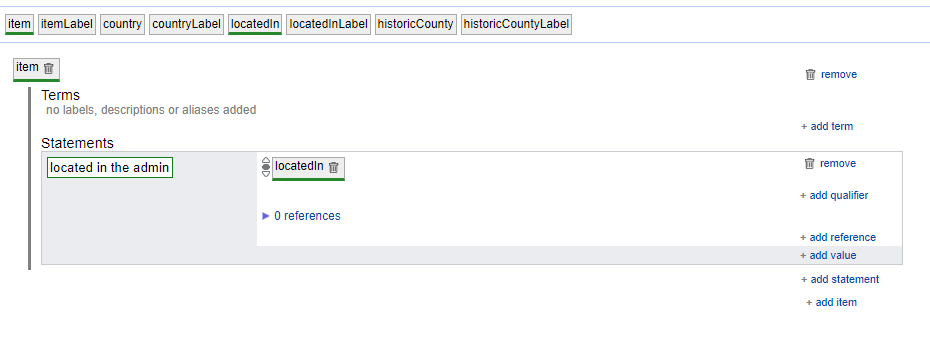
One of the next pages allows you to review all of the statements that will be “uploaded” when you hit the button for review, and also a page provides you with any warnings for things you may have missed.
For my current case that stated that I wasn’t adding references yet, which I was aware of, but chose to skip in this case.
Then a small edit summary is needed and you can hit the “Upload edits” button!
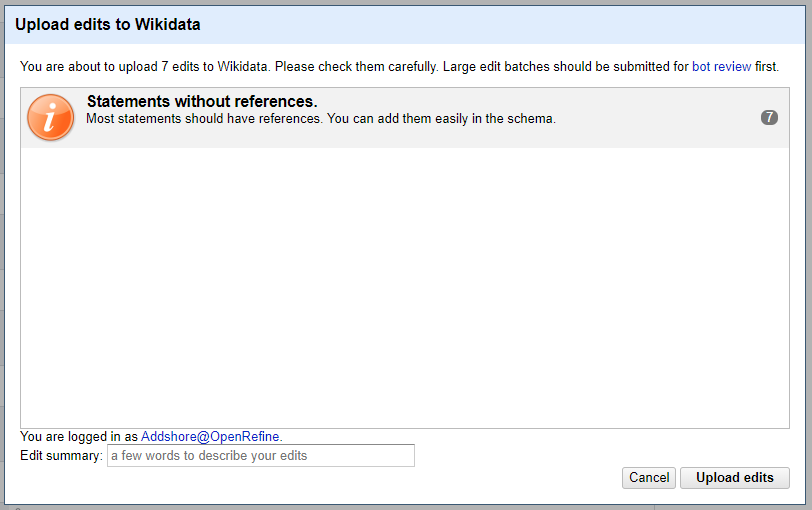
The edits
You can see the initial batches of edits in the editgroups tool (which indexes this sort of batched editing) here and here.

The edit groups tool is helpfully linked in the edit summary of the batch of edits.
One issue (not editing / logged out)
With version 3.3 I ran into one issue where my Wikidata session would apparently get logged out and OpenRefine and the Wikidata Toolkit (which OpenRefine uses) would choke on this case.
I already filed a bug here and the ability to logout and log back in again should be fixed with the next OpenRefine release! (It look less than 3 hours for the patch to get written and merged)
Further
I have already continued editing with OpenRefine beyond this first basic batch and hope to continue writing some more posts, but for now I hope this very basic example serves someone well for a small set of initial edits.
I’d love to see more integration with the Wikidata Query Service and OpenRefine. I’m sure it is probably in the pipes. But with the workflow followed in this blog post there is a lot of back and forth between the two, creating a CSV, downloading it, uploading to OpenRefine, making changes etc. And in order to then continue an existing project with fresh data, you need to repeat the whole process.
Great. This will help me a lot in editing editions of Brazilian librarians that I do on Wikidata. Thank you.