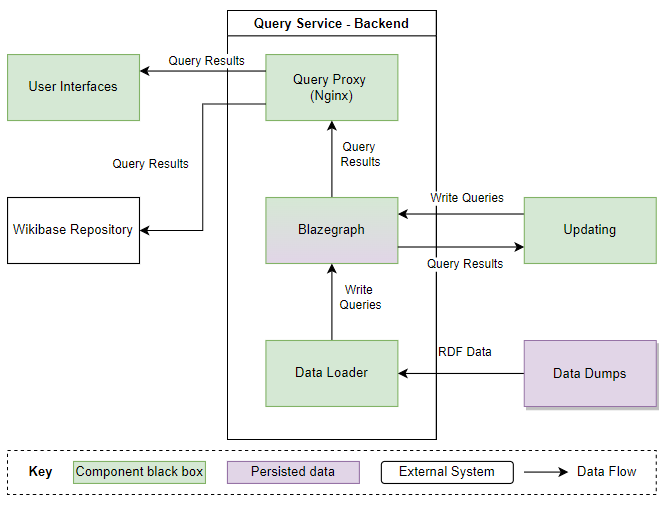
The Wikidata Query Service (WDQS) sits in front of Wikidata and provides access to query its data via a SPARQL API. The query service itself is built on top of Blazegraph, but in many regards is very similar to any other triple store that provides a SPARQL API.
In the early days of the query service (circa 2015), the service was only run by Wikidata, hence the name. However, as interest and usage of Wikibase continued to grow more people started running a query service of their own, for data in their own Wikibase. But you’ll notice most people still refer to it as WDQS today.
Whereas most core Wikibase functionality is developed by Wikimedia Deutschland, the query service is developed by the search platform team at the Wikimedia Foundation, with a focus on wikidata.org, but also a goal of keeping it useable outside of Wikimedia infrastructure.
The query service itself currently works as a whole application rather than just a database. Under the surface, this can roughly be split into 2 key parts
- Backend Blazegraph database that stores and indexes data
- Updater process that takes data from a Wikibase and puts it in the database
This actually means that you can run your own query service, without running a Wikibase at all. For example, you can load the whole of Wikidata into a query service that you operate, and have it stay up to date with current events. Though in practice this is quite some work, and expense on storage and indexing and I expect not many folks do this.
Over time the updater element of the query service updater has iterated through some changes. The updater now packaged with Wikibase as used by most folks outside of the Wikimedia infrastructure is now 2 steps behind the updater used for Wikidata itself.
The updater generations look something like this:
- HTTP API Recent Changes polling updater (used by most Wikibases)
- Kafka based Recent Changes polling updater
- Streaming updater (used on Wikidata)
Let’s take a look at a high-level overview of these updaters, what has changed and why. I’ll also be applying some pretty arbitrary / gut feeling scores to 4 categories for each updater.
Fundamentally they all work in the same way, somehow find out that entities in a Wikibase have changed, get the new data from the wikibase, and update the data in one or more blazegraph backends using a couple of differing methods.
HTTP API polling updater
Simplicity Score: 9/10
Legacy Score: 6/10
Scalability Score: 3/10
Reliability Score: 4/10
The HTTP API polling updater was the original updater likely dating back to 2014/2015. It makes use of the MediaWiki recent changes data and API, normally polling every 10 seconds to look for new changes in the namespaces that Wikibase entities are expected to be found. If changes are detected, it will retrieve the new data, removing old data from the database and storing this new data.
As the updater makes use of a MediaWiki core feature no additional extensions, services or functionality need to be deployed to a Wikibase. It’s nice and easy to set up, requires minimal resources and is quite easy to reason with. So, high simplicity score.

A middle ground score for legacy is given, as this is the oldest updater, however still used widely by Wikibases around the world.
When judging scalability, we have to look at Wikidata. This updater would no longer work very well for the number of changes on Wikidata (let’s say 600 edits per minute) and the number of backend query service databases that those changes need to make their way to (12+ currently). This updater was designed to point at a single blazegraph backend.
By default Recent Changes only store 30 days’ worth of data, so if your updater breaks for 30 days and you don’t notice, you’ll need to reload the data from scratch. For small wikibases, this is one of the most noticeable and annoying things to happen.
Kafka based polling updater
Simplicity Score: 5/10
Legacy Score: 9/10
Scalability Score: 5/10
Reliability Score: 7/10
I’ll gloss over the Kafka polling updater, as this was never generally used in the Wikibase space and only ever in Wikimedia production for Wikidata. It was used roughly between 2018 (created in T185951) and 2021.
At a high level, this updater simple replaced the MediaWiki recent changes HTTP API with a stream of recent changes that were written to Kafka by various event-related extensions for MediaWiki. These events contained similar information that the recent changes API would provide, such as page title, namespace, and from this, the updater can determine what entities have changed.
This loses points for simplicity, as it requires both running of Kafka, and also extra extensions in MediaWiki to emit events. Top scores for legacy, as no one uses this solution anymore. Some scalability issues were solved, such as the elimination of repeated hits to the MediaWiki API, but as with the HTTP updater the total process is still duplicated as the number of backends scale-up, and writes to backends are not very efficient. But as this didn’t rely on the public HTTP API, instead on an internal Kafka service, it can have some extra points for reliability.
Streaming updater
Simplicity Score: 3.5/10
Legacy Score: 1/10
Scalability Score: 9/10
Reliability Score: 9/10
The streaming updater was fully rolled out to Wikidata at the end of 2021 (see T244590) and came with some more significant changes to the update process.
Simplicity decreases due to more components making up the process, as well as more complicated RDF diffing on updates. Low legacy score as its currently in use and actively maintained by the Wikimedia search platform team. It solves a variety of scaling issues for Wikidata with some insane increase in updater performance, and on the whole, due to this factor and more is more reliable.
Similar to the Kafka based polling updater the information about when entities changed comes from Kafka. A single “Producer” listens to this stream of entity changes producing another stream of RDF changes that need to happen in the change. This stream of RDF changes is then listened to by a “Consumer” on each backend which runs write queries against the backend to update the data stored. Note the “Single Host” box in the diagram below.

Some major wins when it comes to this new implementation are:
- Streaming rather than polling, so no waiting in between polls
- Entity changes and the RDF from Wikibase are only retrieved once by the Producer in situations where multiple backends run
- Only RDF changes are written into the database rather than removing all triples associated with an entity and rewriting new triples. This reduces blazegraph write load, as well as increases update speed.
These effects can be seen clearly on Wikidata. The number of requests to the API to retrieve RDF data for Wikibase entities has dropped (less load on MediaWiki). And in cases where a backend falls behind due to some issue and is then fixed, the backend will very quickly catch back up with the current state of Wikidata rather than taking hours.
After setting up a local wikibase from the wikibase image and importing all the data from loadData how do you go about running the update streamer from the last date of the Dump ?
You should just run the updater with the parameters of wikidata and it should all work.
You should find a runUpdater script near loadData