Back in 2019 I wrote a blog post called Your own Wikidata Query Service, with no limits which documented loading a Wikidata TTL dump into your own Blazegraph instance running within Google cloud, a near 2 week process.
I ended that post speculating that part 2 might be using a “pre-generated Blazegraph journal file to deploy a fully loaded Wikidata query service in a matter of minutes”. This post should take us a step close to that eventuality.
Wikidata Production
There are many production Wikidata query service instances all up to date with Wikidata and all of which are powered using open source code that anyone can use, making use of Blazegraph.
Per wikitech documentation there are currently at least 17 Wikidata query service backends:
- public cluster, eqiad: wdqs1004, wdqs1005, wdqs1006, wdqs1007, wdqs1012, wdqs1013
- public cluster, codfw: wdqs2001, wdqs2002, wdqs2003, wdqs2004, wdqs2007
- internal cluster, eqiad: wdqs1003, wdqs1008, wdqs1011
- internal cluster, codfw: wdqs2005, wdqs2006, wdqs2008
These servers all have hardware specs that look something like Dual Intel(R) Xeon(R) CPU E5-2620 v3 CPUs, 1.6TB raw raided space SSD, 128GB RAM.
When you run a query it may end up in any one of the backends powering the public clusters.
All of these servers also then have an up-to-date JNL file full of Wikidata data that anyone wanting to set up their own blazegraph instance with Wikidata data could use. This is currently 1.1TB.
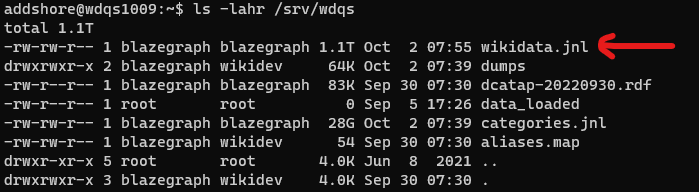
So let’s try and get that out of the cluster for folks to use, rather than having people rebuild their own JNL files.
Getting the JNL file out
At least one of the query service backends in Wikidata production is normally used for testing. At this current point in time that is wdqs1009.
In order to safely copy the JNL file blazegraph needs to be stopped. This was done in coordination with the WMF SRE team and the WMF Search platform team as currently, first Puppet needs to be disabled, and then systemctl stop wdqs-blazegraph.service run.
The first route out of production was via another host that had 1.1TB of disk space free, so the file was copied to that host using some internal tool. From there I used s3cmd to copy the large file into a Google cloud bucket.
| Process | Time |
| Copy between machines | 3 hours |
| Copy to a bucket | 4 hours |
| Copy of a compressed version to a bucket | 1 hour 45 minutes |
In the future, we can probably eliminate this initial copy to a second machine before copying to a Google cloud bucket, as the copy via s3cmd appeared to take a similar amount of time and could likely be added to the query service hosts.
Another thing to note here is that the JNL file does compress rather well, and a compressed version of the file could be useful for some use cases, as I will detail below, downloading 1.1TB is not always a cheap thing to do. However, the process of compression and decompression here also takes multiple hours.
addshore wikidev 1.1T Sep 5 17:11 wikidata.jnl
addshore wikidev 342G Sep 6 21:02 wikidata.jnl.zip
addshore wikidev 306G Sep 6 22:04 wikidata.jnl.pbzip2.bz2
addshore wikidev 342G Sep 5 17:11 wikidata.jnl.gzCode language: CSS (css)The Google cloud bucket
The initial bucket for this blog post is just called addshore-public-test-us and is a public bucket in the US, however Requester pays is enabled. So if you want to download from this bucket, and there is a network egress charge, it will be billed to your Google cloud project.
Whenever a user accesses a Cloud Storage resource such as a bucket or object, there are charges associated with making and executing the request.
Normally, the project owner of the resource is billed for these charges; however, if the requester provides a billing project with their request, the requester’s project is billed instead.
Requester Pays: cloud.google.com
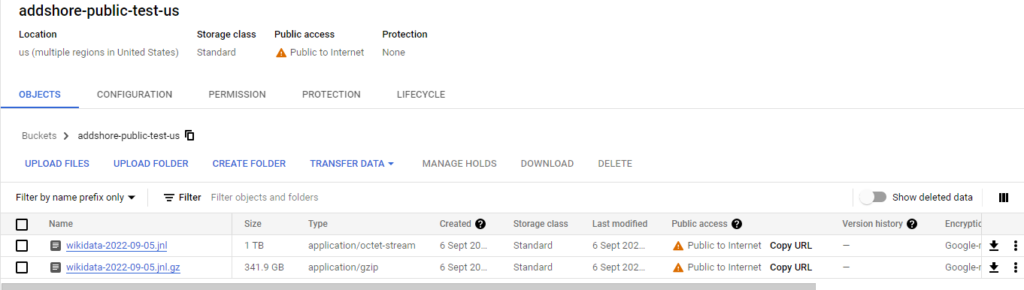
Of course, storing a 1.1TB file is not without a cost. For the month of September storing a single JNL file in a cloud bucket for folks to be able to download in public costs roughly €30. For now I
Downloading the JNL
NOTE: Downloading the JNL outside of Google Cloud will result in ~€121 to your Google Cloud project
Making use of the gsutil tool the command you need is:
gsutil -u [YOUR_PROJECT_NAME] cp gs://addshore-public-test-us/wikidata-2022-09-05.jnl [LOCAL_PATH_ON_MACHINE]Code language: JavaScript (javascript)[YOUR_PROJECT_NAME] should be replaced with the name of a Google cloud project that you will use for billing.
[LOCAL_PATH_ON_MACHINE] should be replaced with a path on the machine that you are running gsutil on that you wish to copy the file to.
From the reports of folks trying this so far downloading to a Google Cloud machine took 4-5 hours, and downloading to a machine not within Google cloud infrastructure took roughly overnight.
Thanks to @epoz & Simon for the testing.
Using the file
You must use the wdqs flavoured blazegraph to be able to read this JNL file, and ideally, you would use the exact version that generated the file in the first place.
You can read more about how to run your own wdqs flavoured blazegraph at https://www.mediawiki.org/wiki/Wikidata_Query_Service/Implementation/Standalone
You can find the latest docker images for wdqs maintained by Wikimedia Deutschland at https://hub.docker.com/r/wikibase/wdqs/tags
I recommend running blazegraph first so that it generates a new JNL in the location that it wants to. Then turn it off and swap that file out for the file that you have downloaded. Turning blazegraph back on you should then be able to query all of the data. If you already know where the JNL file would be for your installation you can go ahead and put it there right away!
Next steps
For now, I will not schedule into my calendar for this copying process to be done, however, I’ll try to leave the wikidata-2022-09-05.jnl file in place for at least the month of October 2022. On the whole, it’d be great if someone else could foot the bill, perhaps even the bill for folks downloading the file.
Extracting the JNL from Wikidata production was rather painless, though it does need some human intervention that would be good to minimise.
It could make sense for this JNL file to periodically end up on dumps.wikimedia.org rather than only heading out to this Google Cloud bucket. That would also avoid the issue of needing to have folks that download the file pay for the data egress.
I still want to experiment with a 1 liner or a button push which could see you with a fully loaded endpoint to query to your heart’s desire as fast as possible. The thing that currently worries me here is the report that it took 3-4 hours to download this file from the bucket onto a VM even within the Google cloud infrastructure. I imagine I may have to do something with images, be that container, disks or something else.
Want to help cover the costs of this experiment so far? Buy me a coffee!
I’m now downloading your JNL file (thank you!) but still would like to handle my own and keep it updated (e.g. I’m using this https://github.com/wikimedia/wikidata-query-rdf/blob/master/docs/getting-started.md ).
My main issue is about the insane amont of log output produced by runBlazegraph.sh, which has huge impact on speed, and – as I’m not really into Java – still I don’t understand which parameters to enforce (and where).
I’ve tried to append many -D parameters on the command line aggregated in runBlazegraph.sh (e.g. -Dcom.bigdata.level=WARN ), or to override Log4j properties file to use multiple different combinations inside it ( -Dlog4j.configuration=file:blabla/myown/log4j.properties ), but still as lots of DEBUG output such as
14:14:35.824 [main] DEBUG com.bigdata.io.DirectBufferPool –
14:14:36.247 [com.bigdata.journal.Journal.executorService1] DEBUG com.bigdata.sparse.TPS …
Any hint about this?
Thanks!
Hey there!
Are you using the docker images, or the wikidata-query-rdf code directly?
If the former, then https://github.com/wmde/wikibase-release-pipeline/pull/364 might be useful for you (coming in the next release)
No, I’m directly on wikidata-query-rdf. And I directly edit the runBlazegraph.sh file to append my parameters, with no success.
Probably I’m using some wrong option. Difficult to guess which are the right ones…
Your best bet will be to pop into IRC and talk to the search platform team.
You’ll find them on Libera.Chat in #wikimedia-search