Over the years I have created a few little side projects, as well as working on other folks’ Wikibases, and of course Wikidata. And the one thing that I still wish would work better out of the box is reconciliation.
What is reconciliation
In the context of Wikibase, reconciliation refers to the process of matching or aligning external data sources with items in a Wikibase instance. It involves comparing the data from external sources with the existing data in Wikibase to identify potential matches or associations.
The reconciliation process typically follows these steps:
- Data Source Identification: Identify and select the external data sources that you want to reconcile with your Wikibase instance. These sources can include databases, spreadsheets, APIs, or other structured datasets.
- Data Comparison: Compare the data from the external sources with the existing data in your Wikibase. This step involves matching the relevant attributes or properties of the external data with the corresponding properties in Wikibase.
- Record Matching: Determine the level of similarity or matching criteria to identify potential matches between the external data and items in Wikibase. This can include exact matches, fuzzy matching, or other techniques based on specific properties or identifiers.
- Reconciliation Workflow: Develop a workflow or set of rules to reconcile the identified potential matches. This may involve manual review and confirmation or automated processes to validate the matches based on predefined criteria.
- Data Integration: Once the matches are confirmed, integrate the reconciled data from the external sources into your Wikibase instance. This may include creating new items, updating existing items, or adding additional statements or qualifiers to enrich the data.
Reconciliation plays a crucial role in data integration, data quality enhancement, and ensuring consistency between external data sources and the data stored in Wikibase. It enables users to leverage external data while maintaining control over data accuracy, completeness, and alignment with their knowledge base.
Existing reconciliation
One of my favourite places to reconcile data for Wikidata is by using OpenRefine. I have two previous posts looking at my first time using it, and a follow-up, both of which take a look at the reconciliation interface (You can also read the docs).
wikibase-edit (a NodeJS library by maxlath) also has some built-in experimental reconciliation that I’m yet to try, so perhaps I should be trying to write node code rather than Python code?
I believe the fast-run mode of Wikidata Integrator also has some sort of reconciliation built in, as this can lead to editing / creating items, rather than just creating them? (But I’m yet to use this too)…
Most existing reconciliation systems make use of the query service or in some cases the search functionality of a Wikibase.
Example process
In a demo that I’m currently working on, I am importing a bunch of data into a Wikibase from Wikidata for manipulation, refining, and connecting and implementing with additional data sources.
One such item for example might be the Empire State Building. I’m initially interested in the item itself, its Wikidata ID, but also other external identifiers. In order to make reconciliation possible at all, I need to import the item and create local versions of the Wikidata properties, maintaining the mapping to show they are the same as another property on Wikidata.
For now, this would be something like below, which is P133 on my Wikibase, but actually P6706 on Wikidata.
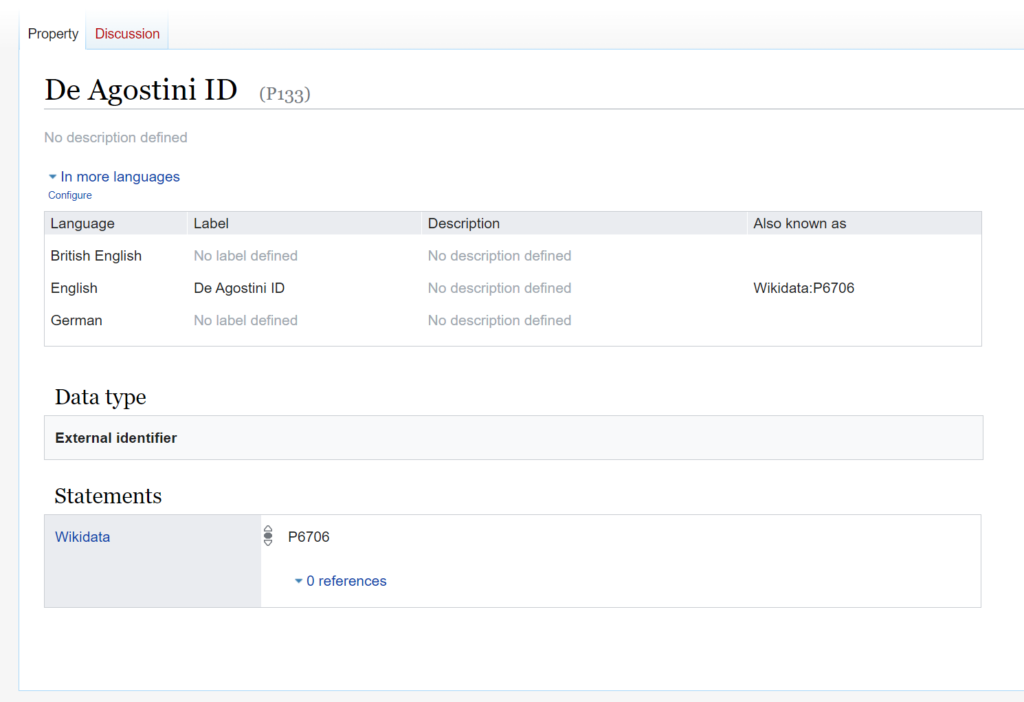
Then for this particular statement, I can use a simple query service query to check if any item exists on the Wikibase that already has a “De Agostini ID” that matches the data I am trying to import.
SELECT * {
?item <https://overture-demo.wikibase.cloud/prop/direct/P133> "Foo"
} Code language: HTML, XML (xml)Sometimes, which right now seems to be the case for Wikibase Cloud, the query service can also be a bit lagged, and that can lead to some requirements to code in some fallbacks.
For my import case, this is where the label/description uniqueness constraints seem to come in, as I can try a write, and if it fails, know the entity I was trying to create already exists. Thought note, it’s a hack!
# Write and catch errors, as wikibase.cloud can be a bit slow in allowing us to lookup existing things sometimes
try:
property.write(login=wb_login,entity_type='property', property_datatype=value['datatype'])
map[key]['id'] = property.wd_item_id
print("Created property: " + value['label'] + " is " + property.wd_item_id)
except Exception as e:
if 'label-conflict' in str(e):
# Add it to the map
map[key]['id'] = re.search(r'\[\[Property:([^|]+)\|', str(e)).group(1)
print("Property already exists: " + value['label'] + " is " + map[key]['id'])
else:
print("Error creating property: " + str(e))
exit()Code language: Python (python)What could have been?
Back in 2013 in my History of Wikibase post I mention T54385 which was the idea of querying by one query and one property. Probably if we had gone down that route back then we would have much better reconciliation options for Wikibase today. Such a query would likely have been implemented much closer to Wikibase itself, rather than in an external system such as a SPARQL query endpoint which has a long complex update procedure.
Another tool was created along the way for Wikidata that wrapped the SPARQL endpoint and provided a simple lookup for entities based on a property value pair. This simple interface already greatly simplified coding projects with a simple API call rather than a more complicated SPARQL query. However I can’t find the tool today, perhaps it no longer exists? and as I remember, it only made it to Wikidata, not Wikibase.
There has always been talk of moving the OpenRefine reconciliation API, which currently exists as a separate service, closer to Wikibase core. In T244847 you can read more about the current status and thoughts around this service.
More recently an extension was worked on at WMDE called WikibaseReconcileEdit. This extension has some great groundwork for an editing process with APIs provided by a Wikibase extension where reconciliation is built in and handled by the application and API rather than the user. The extension was only created for the Open!Next project and is not really usable outside of this unless your reconciliation needs to match the Open!Next project requirements (reconciling based on URL). But I highly recommend giving the README a read, and looking at the edit payloads. These include a batch edit API!
In the example below, an item label would be created or updated, based on the match to P23, which is only referred to in the payload by name “identifier-name”, which could just as well be “Wikidata ID”, “ISBN” etc.
{
"wikibasereconcileedit-version": "0.0.1/minimal",
"labels": {
"en": "Item #3 to reconcile with"
},
"statements": [
{
"property": "identifier-name", // P23
"value": "https://github.com/addshore/test3"
}
]
}Code language: JSON / JSON with Comments (json)To conclude
There are quite a few options out there, non of which are perfect.
When wanting a UI experience I’d go with OpenRefine, though this can be annoying when using non Wikidata Wikibases as you need to run the reconciliation service yourself, and Wikibase cloud and most other hosts don’t currently provide this.
When scripting some data ingestion, right now I mainly find myself writing code to solve this problem with a whole bunch of fallbacks. It’s certainly one of the biggest drags whenever I start a little Wikibase project or data ingesting in general by script.
My personal opinion is that reconciliation needs to become a core feature of Wikibase, as it is extremely core to most workflows for data manipulation. If you’re editing a Wikibase, you are probably doing reconciliation and just not thinking about it.
Any plans looking into LLM and reconciliation? I feel we in general don’t use Wikibase and Wikidata more than as an container for uploaded data… the potential of learning from data added in Wikidata and recommend sources or properties could I guess add much value…. As Entity schemas don’t scale I feel is an indication that even the approach is good it’s to complex for the community…
LLM reconciliation sounds interesting, it could certainly slap a simple and easy to understand façade onto the problem of reconciliation. But I have no plans!
I think an LLM based interface for the Wikidata and or Wikibase query UI though could be a great investment!!!
Some ML researchers says they will try use LLM for The dataset they have produced that is tight integrated with WD
We have added all Swedish PMs into WD since 1885 and are the best dataset for this data… the ML researcher use this for producing TEI of written Swedis PM docs and have who is speaking same as WD qnumber
https://github.com/welfare-state-analytics/riksdagen-corpus
I try to get them start using Wikibase but no success yet its just csv files https://github.com/welfare-state-analytics/riksdagen-corpus/tree/main/corpus/protocols
——-
Very cool part in this project is when doing a PR they run tests of the the data and also checks the quality of Wikidata and find errors in WD https://github.com/welfare-state-analytics/riksdagen-corpus/actions/workflows/push.yml
——
I have tried to get them to start use ShEx with no success
https://github.com/salgo60/Wikidata_riksdagen-corpus/issues/129
Feels everything moves to slow ;-)