At the start of this year, I spent some time visualizing the Wikibase ecosystem by making use of the data that has been collected on wikibase.world. As part of that, I tried to focus in on Wikibase Suite, trying to determine how many possible installations there were making use of the container images, and or the newer Wikibase Suite Deploy thing.
I came to the number 33, based on the fact that there were this many sites online on wikibase.world that have an exact match to the MediaWiki versions that have been released as part of the Wikibase Suite container images. And in all cases, this would be an overestimate, given that these versions would also be installed by some not using the images, so the likely number would be closer to ~16…
And of the 33 sites that might possibly be using “suite” as they are on the same version at least, probably 50% are installed via other means, so the “suite” installations probably account for ~16 of the wikibases in wikibase.world at a guesstimate, with ~50 using other methods and 711 using wikibase.cloud.
9th December 2025 Edit
Apparently this post attracted some attention, and I want to make it clear that “Wikibase suite” here is specifically talking about the packaging up of the container images / docker images into some single installable reusable magic component, and support system around it.
I personally believe the container images themselves are a great asset, and the idea of a suite of recommended extensions and applications that should be delivered alongside a Wikibase is also an asset that the ecosystem does need.
Also looking at the “Wikibase Suite Team” board for “Sprint 9 (Nov 25 – Dec 9)” federation is a key topic that is currently being worked on, and tasks like T404547 [Self-Hosting Ops] Define metric for ease of self-hosting show that the team is / has moved away from only thinking about the magic packaged layer.

Updated count
10 months on from this first look, while visiting the Wikimedia Germany offices, I found the need once again to try to come up with concrete numbers in terms of the users of Wikibase Suite, where my general motive would be to convince WMDE that resources are better spent in other places, such as supporting the underlying software, not just this fancy wrapper on top.
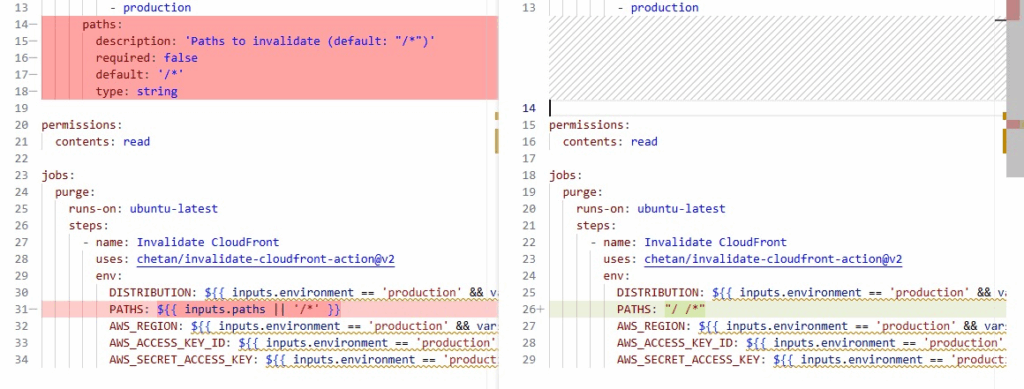
And with this new analysis, my revised number is roughly 18, of which 9 are possibly active, and 2 are likely lost to bot spam. You can find the list via this rather lengthy wikibase.world query.