It’s been somewhere between 2 and 3 years since WMDE took over WBStack, turned it into wikibase.cloud. During this time, my techy focus has slowly shifted away from the world of Wikibase, though I still enjoy following along and working on other Wikimedia areas.
Here I will ramble on about what I saw in terms of potential for wikibase.cloud within the Wikibase ecosystem, as well as what developments have happened within the past years.

The initial problems, goals and dreams
From An introduction to WBStack, I said:
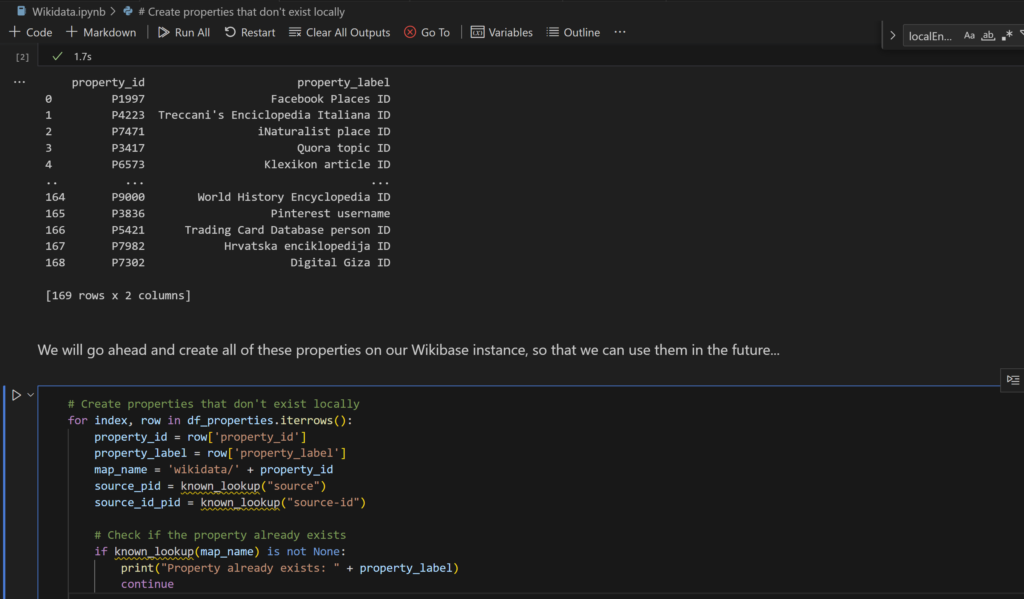
The idea behind the project is to provide Wikibase and surrounding services, such as a blazegraph query service, query service ui, quick statements, and others on a shared platform where installs, upgrades and maintenance are handled centrally.
Now, this is fairly obvious, and clearly something that wikibase.cloud still offers today, however I didn’t write why!? And this is potentially something that has gotten lost through the years of multiple PMs, multiple engineers, multiple project names etc.