Historically I’m terrible at post Hackathon write ups, though a few do exist… (#hackathon posts). For the past few days I have been attending the Wikimedia Hackathon Northwestern Europe 2026 in Arnhem NL with around 70 other people. Around 42 projects were shown at the showcase, and I want to briefly look at some of those, and also document some of the other things that were going on in my vicinity.
On the whole, this was a great hcakathon, larger than the last NL organized hackathon, a beautifull venue, good organization, good food, good people, lots of conversation, and for me at least, everything was very convenient.
Over the past week I have spent some time writing some code to start running a little bot on the wikibase.world project, aimed at expanding the number of Wikibases that are collected there, and automating collection of some of the data that can easily be automated.
Over the past week, the bot has imported 650 Wikibase installs that increases the total to 784, and active to 755.
I mainly wanted to do this to try and visualize “federation” or rather, links between Wikibases that are currently occurring, hence creating P55 (links to Wikibase) and P56 (linked from Wikibase).
Back in 2019 at the start of the COVID-19 outbreak, Wikipedia saw large spikes in page views on COVID-19 related topics while people here hunting for information.
I wrote a notebook to do just this, submitted it for privacy review, and I am finally getting around to putting some of those moving parts and visualizations in public view.
Methodology
It certainly isn’t perfect, but the representation of spikes is much more accurate than looking at a single Wikipedia or set of hand selected pages.
Find statements on Wikidata that relate to COVID-19 items
In this post, I’ll look at some of the ontology mappings that happen between projects, some of the SPARQL that can help you use this ontology in tools, and also some tools to help you explore this complex tree.
I’m using trains as I think they are fairly easy for most folks to relate to, and also don’t have a massively complex tree.
Wikimedia Commons categories quite often contain infoboxes on the right-hand side that link to a variety of resources for the thing the category is covering. And quite often there is a Wikidata item ID present, this is the case for the categories above.
Likewise on Wikidata statements for P373 (Commons category) will often exist for entities that are depicted on Commons.
During my first week at Newspeak house while explaining Wikidata and Wikibase to some folks on the terrace the topic of Dams came up while discussing an old project that someone had worked on. Back in the day collecting information about Dams would have been quite an effort, compiling a bunch of different data from different sources to try to get a complete worldwide view on the topic. Perhaps it is easier with Wikidata now?
Below is a very brief walkthrough of topic discovery and exploration using various Wikidata features and the SPARQL query service.
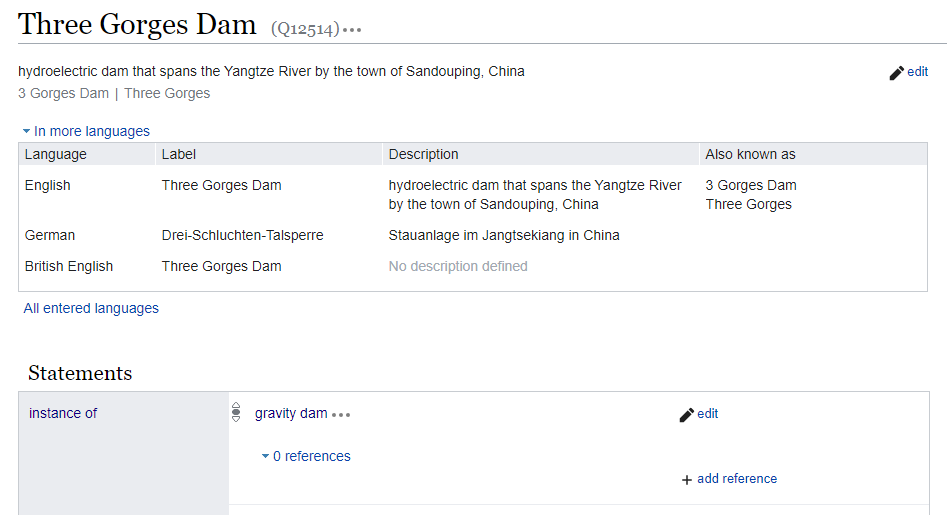
A typical known Dam
In order to get an idea of the data space for the topic within Wikidata I start with a Dam that I know about already, the Three Gorges Dam (Q12514). Using this example I can see how Dams are typically described.
I have long known about OpenRefine (previously Google Refine) which is a tool for working with data, manipulating and cleaning it. As of version 3.0 (May 2018), OpenRefine included a Wikidata extension, allowing for extra reconciliation and also editing of Wikidata directly (as far as I understand it). You can find some documentation on this topic on Wikidata itself.
This post serves as a summary of my initial experiences with OpenRefine, including some very basic reconciliation from a Wikidata Query Service SPARQL query, and making edits on Wikidata.
In order to follow along you should already know a little about what Wikidata is.
Starting OpenRefine
I tried out OpenRefine in two different setups both of which were easy to set up following the installation docs. The setups were on my actual machine and in a VM. For the VM I also had to use the -i option to make the service listen on a different IP. refine -i 172.23.111.140
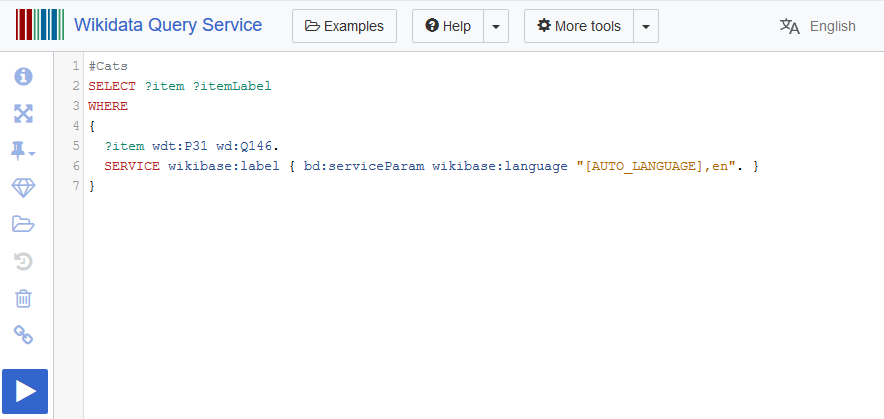
The Wikidata Query Service allows anyone to use SPARQL to query the continuously evolving data contained within the Wikidata project, currently standing at nearly 65 millions data items (concepts) and over 7000 properties, which translates to roughly 8.4 billion triples.
You can find a great write up introducing SPARQL, Wikidata, the query service and what it can do here. But this post will assume that you already know all of that.
Geospatial search is up and running for the Wikidata Query Service! This allows you to search for items with coordinates that are located within a certain radius or within a bounding box.
Along side the the map that can be used to display results for the query service this really is a great tool for quickly visualizing coverage.
Wikidata provides free and open access to entities representing real world concepts. Of course Wikidata is not meant to contain every kind of data, for example beer reviews or product reviews would probably never make it into Wikidata items. However creating an app that is powered by Wikidata & Wikibase to contain beer reviews should be rather easy.