At the end of 2022, I published a Blazegraph JNL file for Wikidata in a Google Cloud bucket for 1 month for folks to download and determine if it was useful.
Thanks to Arno from weblyzard, inflatador from the WMF search platform team, and Mark from the Internet Archive for the recent conversations around this topic.
You can now grab some new JNL files from a few days ago, hosted on either the Internet Archive or Cloudflare R2.
Cloudflare R2 (faster, won’t be around forever)Deleted December 2023- Internet Archive (slower, will be around for quite some time)
If you want to use these files, check out the relevant section in my previous post.
Host changes
The use of a Google Cloud bucket came with a large downside of data egress cost overheads being around 121 Euros per download when exiting Google Cloud. Some folks still found the file useful despite this cost, and some folks also just used it inside Google Cloud.
After Arno reached out to me, I thought about who might be up for hosting multiple terabytes of data for some time with free data transfer (and ideally covering hosting costs), and ended up emailing Mark from the Internet Archive, who said I should just go ahead and upload it.
Conveniently archive.org has an S3 like API to use, so sending the data there should be as easy as sending it to Google Cloud.
While talking to inflatador about extracting a new JNL file from a Wikimedia production host, they informed me that Cloudflare R2 (S3 compatible buckets) have free data egress. 🥳
So, moving forward I’ll try to provide the latest JNL file on Cloudflare R2, and archive.org can store a few historical copies as well.
Uploading the files
I struggled for multiple days to make the uploads to both targets actually complete to 100%, as can be seen by the rather network-intensive period for the wdqs1009 host in Wikimedia production that I was using to retrieve the JNL file from.
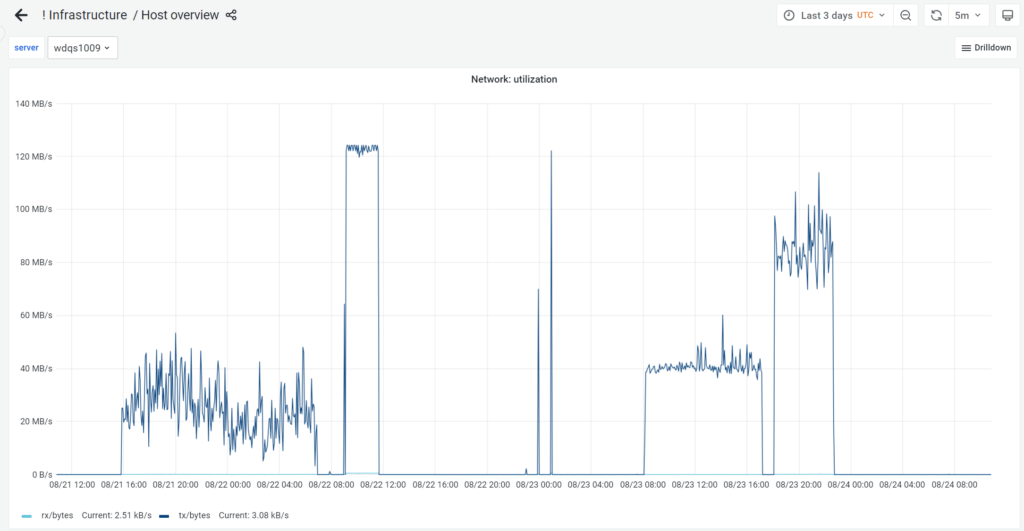
The first transfer was to archive.org which worked first time, though I only used CURL, and am unsure if the validity of the transfer would have actually been checked?
curl --location --header 'x-amz-auto-make-bucket:1' \
--header 'x-archive-meta01-subject:wikidata' \
--header 'x-archive-meta02-subject:jnl' \
--header 'x-archive-meta-mediatype:data' \
--header 'x-archive-meta-licenseurl:https://creativecommons.org/publicdomain/zero/1.0/' \
--header "authorization: LOW aaa:bbb" \
--upload-file /srv/wdqs/wikidata.jnl \
http://s3.us.archive.org/addshore-wikidata-jnl/2023-08-21.jnlCode language: JavaScript (javascript)It took roughly 15 hours to transfer the 1.2TB file, which is ≈ 80 GB/hour (could probably go faster if using an S3 CLI tool)
Archive.org then seemingly has a bunch of post-processing that happens, so the file was not available to download for another day or so.

R2 couldn’t just take a 1.2TB file in a single chunk through a curl file upload, so I looked at tools that would work with it.
I couldn’t figure out how to make s3cmd actually work (which is the tool I used previously), but settled on rclone which is provided as an example in the R2 docs.
The second transfer, which hit 120MB/s was to R2 using the cat command, though this failed with some chunk errors at the end. This could be due to the lack of chunk validity checks, but also could be due to the number of concurrent uploaders I was trying to use at the time (32). (See issue on Github)
As did the third transfer used copyto, which seemingly uploaded 1TB and then failed right at the end. This could have been due to the fact that the query service process on the host restarted and was touching the JNL file.
Finally, the fourth upload worked, taking around 4.5 hours which is ≈ 266.67 GB/hour.
rclone copyto -P /srv/wdqs/wikidata.jnl cloudflare:addshore-wikidata-jnl/2023-08-22.jnl --s3-upload-cutoff=2G --s3-chunk-size=2G --transfers=4 --s3-upload-concurrency=4Download speeds
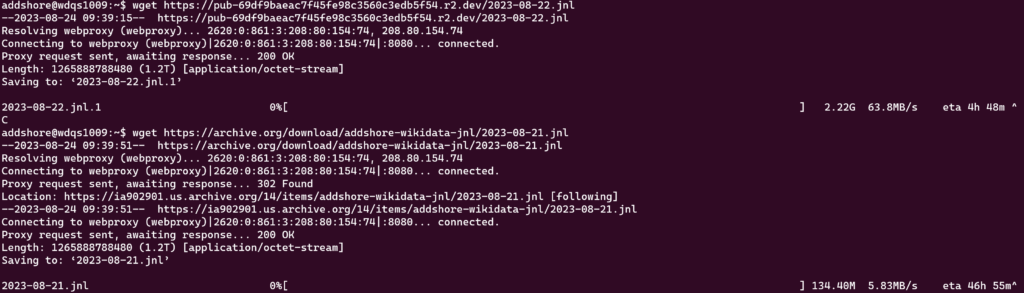
I did a quick check on the download speed from the two new targets with a simple wget, and as expected R2 is significantly faster to download from than archive.org over HTTP.
Is it possible that using some S3 tool to download these files might result in faster download speeds?
Moving forward
Feel free to reach out to me if you want a newer copy of the JNL file published. The whole process should now take less than 12 hours to get a file to archive.org for it to start processing and to get a live file on R2.
There are discussions about providing these JNL files more regularly via a defined process perhaps on dumps.wikimedia.org, and I have opened a ticket to focus that conversation. T344905
Hosting these files on R2 does cost, so feel free to Buy me a coffee to support the cost.
The Linux command ‘axel’ available via apt-get can help speed the download considerably on CloudFlare R2 (pro tip courtesy of inflatador). Thanks Adam for hosting!
It’s actually a good initiative, thank you
I am using this dump to run my own wikidata query service. However, I notice an issue compared to the official wikidata. For some reason SPARQL function is not working, for example:
select * where {http://www.wikidata.org/entity/Q70899 ?p ?wds .
?wds ?ps ?val .
filter(http://wikiba.se/ontology#isSomeValue(?val) || isBlank(?val))
} limit 2
Can you imagining why?
I can’t really tell why,
Indeed this seems to work fine on WDQS itself https://w.wiki/7fh3
How exactly are you running the query on your copy?
Does the other data appear?
Thanks a lot for those tutorials. Is there now a faster approach in 2025 or would you still recommend going that route? Can we update the data starting from this jnl snapshot?
I believe this is still the fastest route, though everything will take even more time now that the data set is larger.
Another thing of note is that the WMF hosted Wikidata query service now has a split graph https://www.wikidata.org/wiki/Wikidata:SPARQL_query_service/WDQS_graph_split
This doesn’t relate to being able to load the data yourself at all I don’t think, but might be of interest in general.
Trying to catch up from the last JNL file posted might take you quite some time, and you might be better off loading it yourself.
It might be worth popping into the Wikibase related telegram chats, as folks there (such as James Hare) might be able to help sort you out with a newer JNL file?