Back in 2019 I wrote a blog post called Your own Wikidata Query Service, with no limits which documented loading a Wikidata TTL dump into your own Blazegraph instance running within Google cloud, a near 2 week process.
I ended that post speculating that part 2 might be using a “pre-generated Blazegraph journal file to deploy a fully loaded Wikidata query service in a matter of minutes”. This post should take us a step close to that eventuality.
There are many production Wikidata query service instances all up to date with Wikidata and all of which are powered using open source code that anyone can use, making use of Blazegraph.
These servers all have hardware specs that look something like Dual Intel(R) Xeon(R) CPU E5-2620 v3 CPUs, 1.6TB raw raided space SSD, 128GB RAM.
When you run a query it may end up in any one of the backends powering the public clusters.
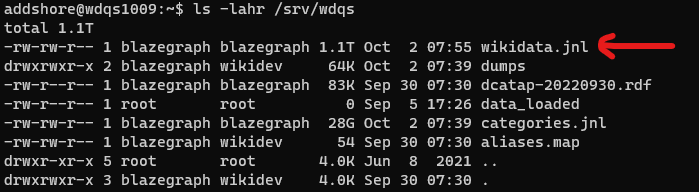
All of these servers also then have an up-to-date JNL file full of Wikidata data that anyone wanting to set up their own blazegraph instance with Wikidata data could use. This is currently 1.1TB.
So let’s try and get that out of the cluster for folks to use, rather than having people rebuild their own JNL files.
The Wikidata Query Service allows anyone to use SPARQL to query the continuously evolving data contained within the Wikidata project, currently standing at nearly 65 millions data items (concepts) and over 7000 properties, which translates to roughly 8.4 billion triples.
You can find a great write up introducing SPARQL, Wikidata, the query service and what it can do here. But this post will assume that you already know all of that.