Wikimedia Enterprise is a new (now 1-year-old) service and offered by the Wikimedia Foundation, via Wikimedia, LLC.
This is a wholly-owned LLC that provides opt-in services for third-party content reuse, delivered via API services.
In essence, this means that Wikimedia Enterprise is an optional product that third parties can choose to use that repackages data from within Wikimedia projects in a more useful, more reliable, and stable format presenting them primarily via data downloads and APIs, with profits going into the Wikimedia Foundation.
Want to find out more? Read the FAQ.
The project and APIs are well documented, and access can be requested for free, but I wanted to spend a little bit of time hands-on with the APIs to get a full understanding of what is offered, the formats, and how it differs from things I know are exposed elsewhere in Wikimedia projects.
Account Creation
Wikimedia Enterprise accounts are separate from any other Wikimedia related accounts, so you’ll need a new one.
In order to get an account you need to fill out a pretty straightforward form (username, password, email, and accept terms). You then need to verify your email address. Tada, you are in!
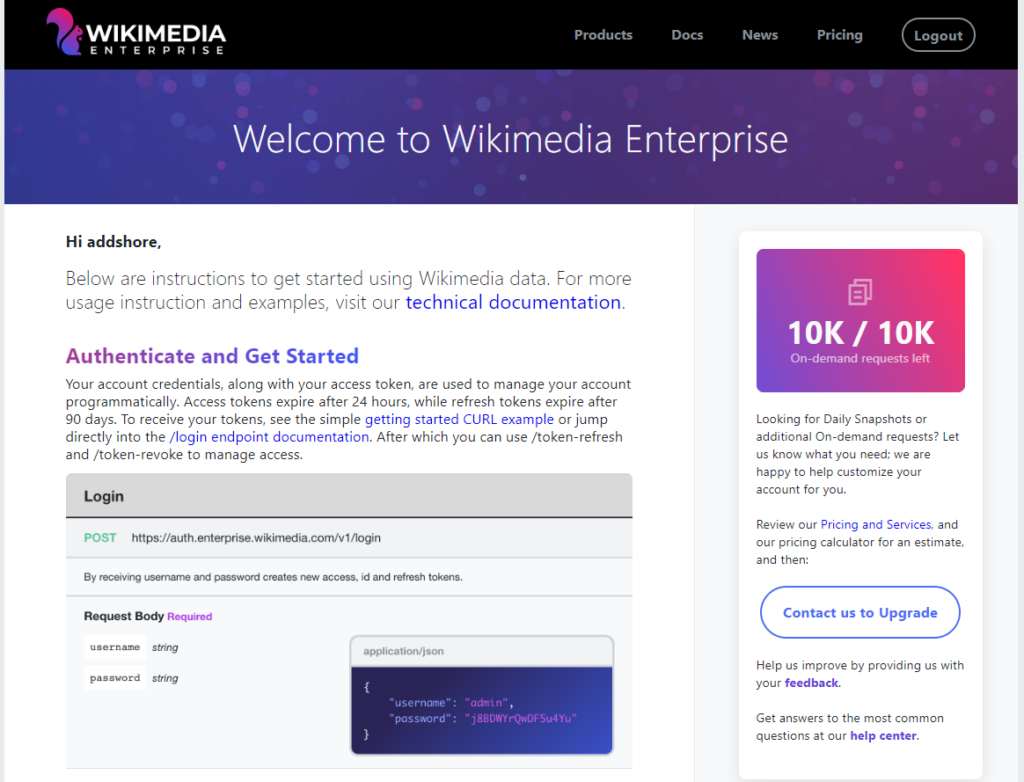
Right away you are directed to the authentication docs and a CURL based example for getting started.
Authentication
Following the CURL based example, authentication is easy…
curl -L https://auth.enterprise.wikimedia.com/v1/login -H "Content-Type: application/json" -d '{"username": "addshore","password":"XXX"}'
{
"id_token": "XXX",
"access_token": "XXX",
"refresh_token": "XXX",
"expires_in": 86400
}Code language: JavaScript (javascript)You can then use the access_token in future API calls (also shown in the curl based example). Such as:
curl -H "Authorization: Bearer ACCESS_TOKEN" -L https://api.enterprise.wikimedia.com/v1/projectsCode language: JavaScript (javascript)You can read more in the authentication docs.
On-Demand API
These APIs allow you to get live information from Wikimedia projects.
The first API is Available projects.
The response of this API is a list of objects, each of which includes some additional metadata about the site.
The example below is snipped for your convenience.
[
{
"name": "Wikipedia",
"identifier": "brwiki",
"url": "https://br.wikipedia.org",
"in_language": {
"name": "Breton",
"identifier": "br"
}
},
{
"name": "Wikeriadur",
"identifier": "brwiktionary",
"url": "https://br.wiktionary.org",
"in_language": {
"name": "Breton",
"identifier": "br"
}
},
...
]Code language: JSON / JSON with Comments (json)The identifiers of these sites can then ben used with the second On-Demand API, Article lookup.
A site identifier and article name can be used to look up current information about that article.
The response of this API includes HTML and wikitext of the current revision, as well as extra metadata all collected into a single response.
Extra metadata includes:
- Page information: Title, identifier, URL, namespace, project, language, redirects to the page
- Revision information: ID, date, comment, tags, editor, templates used, categories used
- Content: HTML, Wikitext, Licence
- Wikidata information: ID, URI, additional entities used (and which aspects)
The example below is snipped for your convenience.
{
"name": "Douglas Adams",
"identifier": 8091,
"date_modified": "2022-10-15T21:28:17Z",
"version": {
"identifier": 1116296313,
"comment": "/* Writing */ {{snf|Roberts|2015|pp=129–130}}: correcting year",
"tags": [
"wikieditor"
],
"editor": {
"identifier": 11630810,
"name": "Peaceray"
}
},
"url": "https://en.wikipedia.org/wiki/Douglas_Adams",
"namespace": {
"name": "Article",
"identifier": 0
},
"in_language": {
"name": "English",
"identifier": "en"
},
"main_entity": {
"identifier": "Q42",
"url": "http://www.wikidata.org/entity/Q42"
},
"additional_entities": [
{
"identifier": "Q42",
"url": "http://www.wikidata.org/entity/Q42",
"aspects": [
"C",
"D.en",
"O",
"S",
"T"
]
},
{
"identifier": "Q5",
"url": "http://www.wikidata.org/entity/Q5",
"aspects": [
"O"
]
},
{
"identifier": "Q8935487",
"url": "http://www.wikidata.org/entity/Q8935487",
"aspects": [
"S"
]
}
],
"categories": [
{
"name": "Category:1952 births",
"url": "https://en.wikipedia.org/wiki/Category:1952_births"
},
...
],
"templates": [
{
"name": "Template:Authority control",
"url": "https://en.wikipedia.org/wiki/Template:Authority_control"
},
...
],
"redirects": [
{
"name": "Douglas Noël Adams",
"url": "https://en.wikipedia.org/wiki/Douglas_Noël_Adams"
},
...
],
"is_part_of": {
"name": "Wikipedia",
"identifier": "enwiki"
},
"article_body": {
"html": "HTML",
"wikitext": "WIKITEXT"
},
"license": [
{
"name": "Creative Commons Attribution Share Alike 3.0 Unported",
"identifier": "CC-BY-SA-3.0",
"url": "https://creativecommons.org/licenses/by-sa/3.0/"
}
]
}Code language: JSON / JSON with Comments (json)Snapshot API
Similar to the On-Demand API there are a few endpoints for listing the snapshots that could be available.
Available Projects and Available Namespaces for example will provide simple lists of project or namespace identifiers that can be used in further requests.
Snapshot Bundle Info provides information about a specific snapshot bundle of a project and namespace combination.
The example below is snipped for your convenience for frwiki namespace 0.
{
"name": "Wikipédia",
"identifier": "frwiki",
"url": "https://fr.wikipedia.org",
"version": "2d8754c299670b10664e1f57db8e180d",
"date_modified": "2022-10-01T05:59:45.170639212Z",
"size": {
"value": 34602.86,
"unit_text": "MB"
}
}Code language: JSON / JSON with Comments (json)Available Snapshots provides a list of all of this snapshot information across a given namespace on all projects.
You can’t actually download any of these snapshots with the initial account access. You need to contact the enterprise team to get further than this and see what is within the snapshots.
Real Time & Batch APIs
These APIs come with the same disclaimer as the snapshot APIs
For access to Realtime APIs, contact us.
The APIs here would be:
- Project Updates (Batch)
- Available Projects (Batch)
- Project Bundle Info (Batch)
- Available Namespaces (Batch)
- Available Projects (Batch)
- Article Updates (Streaming)
- Article Visibility Changes (Streaming)
Similar to above APIs, I imagine access to the higher level meta data / utility APIs would likely be included already, just downloads of batches or files would not.
Further Access
So there is no free out-of-the-box access to all of the APIs and resources provided by Wikimedia Enterprise.
Taking a few steps back I also spotted this on the dashboard once logging in.
Looking for Daily Snapshots or additional On-demand requests? Let us know what you need; we are happy to help customize your account for you.
Review our Pricing and Services, and our pricing calculator for an estimate, and then:
Wikimedia Enterprise Dashboard
This probably makes sense considering the data transfer costs that could be involved in the Snapshot API or Realtime API.
The Internet Archive already has access to these APIs in some way for free, as was announced earlier this year and hopefully, these more streamlined APIs can also be useful to other organizations.