World events often have a dramatic impact on online services. A past example would be the death of Michael Jackson which brought down Twitter and Wikipedia and made Google believe that they were under attack according to the BBC.
Events like the COVID-19 (Coronavirus) pandemic have less instantaneous affect but trends can still be seen to change. Cloudflare recently posted about some of the internet wide traffic changes due to the pandemic and various government announcements, quarantines and lockdowns.
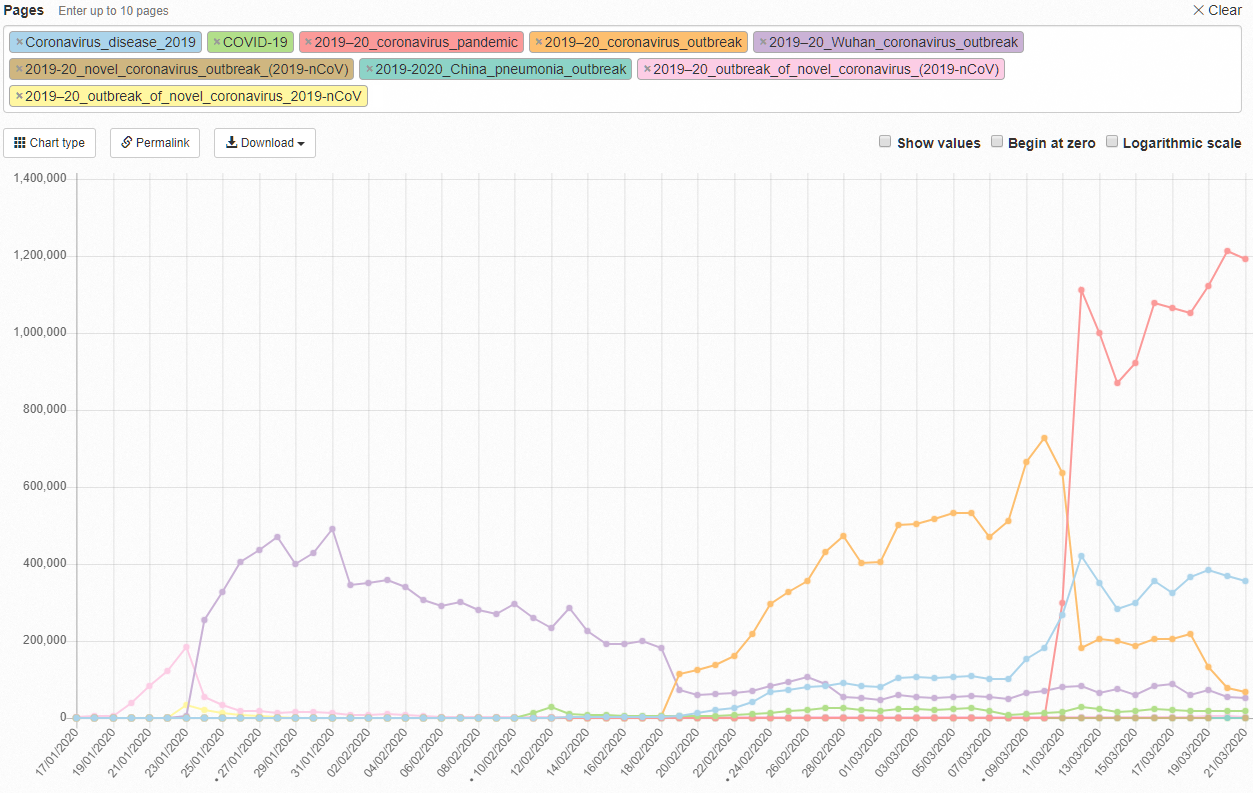
Currently the main English Wikipedia article for the COVID-19 pandemic is receiving roughly 1.2 million page views per day (14 per second). This article has already gone through 4 different names over the past months, and the pageview rate continues to climb.