Back in 2019 I wrote a blog post called Your own Wikidata Query Service, with no limits which documented loading a Wikidata TTL dump into your own Blazegraph instance running within Google cloud, a near 2 week process.
I ended that post speculating that part 2 might be using a “pre-generated Blazegraph journal file to deploy a fully loaded Wikidata query service in a matter of minutes”. This post should take us a step close to that eventuality.
There are many production Wikidata query service instances all up to date with Wikidata and all of which are powered using open source code that anyone can use, making use of Blazegraph.
These servers all have hardware specs that look something like Dual Intel(R) Xeon(R) CPU E5-2620 v3 CPUs, 1.6TB raw raided space SSD, 128GB RAM.
When you run a query it may end up in any one of the backends powering the public clusters.
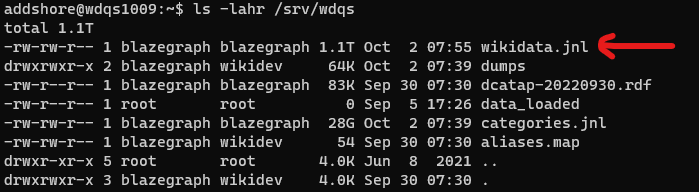
All of these servers also then have an up-to-date JNL file full of Wikidata data that anyone wanting to set up their own blazegraph instance with Wikidata data could use. This is currently 1.1TB.
So let’s try and get that out of the cluster for folks to use, rather than having people rebuild their own JNL files.
It’s time for the 5th instalment of my tech lead digest posts. I switched to monthly for 2 months, but decided to back down to quarterlyish. You can find the other digests by checking out the series.
🧑🤝🧑Wikidata & Wikibase
The biggest event of note in the past months was WikidataCon 2021 which took place toward the end of October 2021. Spread over 3 days the event celebrated Wikidatas 9th birthday. We are still awaiting the report from the event to know how many folks participated, and recordings of talks will likely not be available until early 2022. At which point I’ll try to write another blog post.
Just before WikidataCon the updated strategy for Linked Open Data was published by Wikimedia Deutschland which includes sub-strategies for Wikidata and the Wikibase Ecosystem. This strategy is much easier to digest than the strategy papers published in 2019 and I highly recommend the read. Part of the Wikidata strategy talks about “sharing workload” which reminds me of some thoughts I recently had comparing Wikipedia and Wikidata editing. Wikibase has a focus on Ecosystem enablement, which I am looking forward to working on.
TheWikibase stakeholder group continues to grow and organize. A Twitter account (@wbstakeholders) now exists tweeting relevant updates. Now with over 14 organizational members and 15 individual members, the budget is now public and the group is working on getting some desired features implemented. If you are an organization or individual working in the Wikibase space, be sure to check them out! The group recently published a prioritized list of institutional requirements, and I’m happy to say that some parts of the “Automatic maintenance processes and updating cascades should work out of the box” area that scored 4 have already been tackled by the Wikidata / Wikibase teams.
Toward the end of 2020 I spent some time blackbox testing data load times for WDQS and Blazegraph to try and find out which possible setting tweaks might make things faster.
I didn’t come to any major conclusions as part of this effort but will write up the approach and data nonetheless incase it is useful for others.
I expect the next step toward trying to make this go faster would be via some whitebox testing, consulting with some of the original developers or with people that have taken a deep dive into the code (which I started but didn’t complete).
The Wikidata query service is a public SPARQL endpoint for querying all of the data contained within Wikidata. In a previous blog post I walked through how to set up a complete copy of this query service. One of the steps in this process is the munge step. This performs some pre-processing on the RDF dump that comes directly from Wikidata.
Back in 2019 this step took 20 hours and now takes somewhere between 1-2 days as Wikidata has continued to grow. The original munge step (munge.sh) makes use of only a single CPU. The WMF has been experimenting for some time with performing this step in their Hadoop cluster as part of their modern update mechanism (streaming updater). An additional patch has now also made this useful for the current default load process (using loadData.sh).
This post walks through using the new Hadoop based munge step with the latest Wikidata TTL dump on Google cloudsDataproc service. This cuts the munge time down from 1-2 days to just 2 hours using an 8 worker cluster. Even faster times can be expected with more workers, all the way down to ~20 minutes.
Many users of Wikibase find themselves in a position where they need to change the concept URI of an existing Wikibase for one or more reasons, such as a domain name update or desire to have https concept URIs instead of HTTP.
Below I walk through a minimal example of how this can be done using a small amount of data and the Wikibase Docker images. If you are not using the Docker images the steps should still work, but you do not need to worry about copying files into and out of containers or running commands inside containers.
The Wikidata Query Service allows anyone to use SPARQL to query the continuously evolving data contained within the Wikidata project, currently standing at nearly 65 millions data items (concepts) and over 7000 properties, which translates to roughly 8.4 billion triples.
You can find a great write up introducing SPARQL, Wikidata, the query service and what it can do here. But this post will assume that you already know all of that.
This is a belated post about the Wikibase docker images that I recently created for the Wikidata 5th birthday. You can find the various images on docker hub and matching Dockerfiles on github. These images combined allow you to quickly create docker containers for Wikibase backed by MySQL and with a SPARQL query service running alongside updating live from the Wikibase install.
A setup was demoed at the first Wikidatacon event in Berlin on the 29th of October 2017 and can be seen at roughly 41:10 in the demo of presents video which can be seen below.
Geospatial search is up and running for the Wikidata Query Service! This allows you to search for items with coordinates that are located within a certain radius or within a bounding box.
Along side the the map that can be used to display results for the query service this really is a great tool for quickly visualizing coverage.